![[Data Structures][03-2] 배열을 이용한 리스트의 구현](https://img1.daumcdn.net/thumb/R750x0/?scode=mtistory2&fname=https%3A%2F%2Fblog.kakaocdn.net%2Fdna%2FY8NSR%2FbtriYnCUHYr%2FAAAAAAAAAAAAAAAAAAAAAOiYZh0eeBvcuUXpVcM1Uwt2CvrAL-HqbixcmUN_ZWgu%2Fimg.png%3Fcredential%3DyqXZFxpELC7KVnFOS48ylbz2pIh7yKj8%26expires%3D1772290799%26allow_ip%3D%26allow_referer%3D%26signature%3DvszJfv47fbGiXuFs6GYQ4H6okC4%253D)
본 글은 윤성우의 열혈 자료구조 책을 읽고, 강의를 수강하고 복습한 것을 기록한 글입니다.
강의 교안 또한 참고하여 작성하였습니다.
(강의 교안의 경우 오렌지 미디어에서 다운로드할 수 있습니다)
목차
Chapter 03. 연결 리스트(Linked List) 1
Chapter 03-2: 배열을 이용한 리스트의 구현
- 리스트의 이해
- 리스트 자료구조의 ADT
- 리스트의 ADT를 기반으로 정의된 main 함수
- 리스트의 초기화와 데이터 저장 과정
- 리스트의 데이터 참조 과정
- 리스트의 데이터 삭제 방법
- 배열 기반 리스트
- 배열 기반 리스트의 헤더 파일 정의
- 배열 기반 리스트의 초기화
- 배열 기반 리스트의 삽입
- 배열 기반 리스트의 조회
- 배열 기반 리스트의 삭제
- 리스트에 구조체 변수 저장하기
- PointListMain.c의 일부
- 초기화 및 저장
- 참조 및 조회
- 삭제
- 배열 기반 리스트의 장점과 단점
배열을 이용한 리스트의 구현
리스트의 이해
리스트 자료구조는 데이터를 나란히 저장하며 중복된 데이터의 저장을 허용한다
리스트의 구분
- 순차 리스트 배열을 기반으로 구현된 리스트
- 연결 리스트 메모리의 동적 할당을 기반으로 구현된 리스트
이는 구현 방법을 기준으로 한 구분이다. 따라서 이 두 리스트의 ADT가 동일하다고 해서 문제가 되지는 않는다.
리스트의 특징
- 저장 형태 데이터를 나란히(하나의 열로) 저장한다.
- 저장 특성 중복이 되는 데이터의 저장을 허용한다.
이것이 리스트의 ADT를 정의하는 데 있어서 고려해야 할 유일한 내용이다.
리스트 자료구조의 ADT
리스트의 활용 방안 및 리스트의 특성을 파악하자면 리스트에 기능 과정은 ADT에 반영되지 않고 기능 그 자체가 저장된다. 또한 리스트의 특성이 ADT에 영향을 주지 않는다. ADT의 정의는 상당히 유연하다. 표준화되어있는 것이 아니며 순차적으로 저장할 수 있다면, 그리고 리스트의 특성에 위배되지 않는다면 저장할 수 있다.
실질적으로는 main을 보아야 ADT 기반 자료구조를 이해할 수 있다.

C++, Java와 같은 객체지향 언어에서는 instance를 만들 때 생성자라는 함수가 호출되어 초기화의 과정을 제공받는다.
(리스트의 초기화)
LData는 저장 대상의 자료형을 결정할 수 있도록 typedef로 선언된 자료형의 이름이다.

LFirst(Java에서 객체 생성시, 참조의 시작) -> LNext -> LNext
리스트의 ADT를 기반으로 정의된 main 함수

리스트의 초기화와 데이터 저장 과정
데이터의 관리가 목적인 리스트를 생성한다.
리스트의 초기화
int main(void)
{
List list; // 리스트의 생성
. . . .
ListInit(&list); // 리스트의 초기화
. . . .
}생성 후 리스트 초기화를 진행한다.
초기화된 리스트에 데이터 저장
int main(void)
{
. . . .
LInsert(&list, 11); // 리스트에 11을 저장
LInsert(&list, 22); // 리스트에 22를 저장
LInsert(&list, 33); // 리스트에 33을 저장
. . . .
}리스트에 해당하는 자료의 주소값을 전달하여 해당 입력값을 저장하도록 합니다. 이렇게 저장하면 리스트에 나란히 저장됩니다.
리스트의 데이터 참조 과정
아래의 if문을 보면, LFirst가 data를 참조했다면 True를 반환하고 참조하지 못했다면 False를 반환합니다. 또한 LNext에서도 마찬가지로 data를 참조할 수 없다면 저장할 수 없기 때문에 while문 밖으로 나오게 됩니다.
언어에 따라서 표현방법은 다를 수 있겠지만, 일반적으로 리스트 자료구조의 참조에 있어서는 첫 번째 데이터를 참조하는 방법과 그 이후의 데이터를 참조하는 각각의 함수가 존재합니다. (LFirst, LNext)

데이터 참조 일련의 과정
LFirst -> LNext -> LNext -> LNext -> LNext. . . .
리스트의 데이터 삭제 방법
데이터의 삭제는 일련의 참조 과정 내에서 삭제가 이뤄집니다. (LRemove 혼자서 동작하지 못함)
아래 if(data == 22)를 보면 LFirst에서 참조한 data가 22면 LRemove를 호출하겠다는 의미입니다. 또한 while문을 보면 LNext로 참조한(얻어온) data가 22이면 list가 반환한 값(data == 22)을 삭제하겠다는 의미입니다.

이러한 패턴에 익숙해지는 것이 중요하다.
배열 기반 리스트
배열 기반 리스트의 헤더 파일 정의
#ifndef __ARRAY_LIST_H__
#define __ARRAY_LIST_H__
#define TRUE 1 // '참'을 표현하기 위한 매크로 정의
#define FALSE 0 // '거짓'을 표현하기 위한 매크로 정의
#define LIST_LEN 100
typedef int LData;
typedef struct __ArrayList // 배열기반 리스트를 정의한 구조체
{
LData arr[LIST_LEN]; // 리스트의 저장소인 배열
int numOfData; // 저장된 데이터의 수
int curPosition; // 데이터 차몾위치를 기록
} ArrayList;
typedef ArrayList List;LData 저장할 대상의 자료형 변경을 위한 typedef 선언
배열 기반 리스트를 의미하는 구조체(ArrayList)
리스트의 변경을 용이하게 하기 위한 typedef 선언
void ListInit(Lilst * plist); // 초기화
void LInsert(List * plist, LData * pdata); // 데이터 저장
int LFirst(List * plist, Ldata * pdata); // 첫 번째 데이터 참조
int LNext(List * plist, Ldata * pdata); // 두 번째 이후 데이터 참조
LData LRemove(List * plist); // 참조한 데이터 삭제
int LCount(List * plist); // 저장된 데이터의 수 반환
#endif위의 함수들은 리스트 ADT를 기반으로 선언된 함수들이다.
따라서 배열 기반 리스트로 선언된 함수들의 내용을 제한할 필요가 없다.
배열 기반 리스트의 초기화

numOfData를 0으로 초기화하고 현재 아무 위치도 참조하지 않았으니 curPosition을 -1로 초기화한다.
실제로 초기화할 대상은 구조체 변수의 멤버이다. 따라서 초기화 함수의 구성은 구조체의 정의를 기반으로 한다.
배열 기반 리스트의 삽입

if문의 조건을 보면 저장할 데이터의 수가 배열의 길이를 넘었기 때문에 저장할 공간이 없습니다. 탈출 조건인 것이죠, return으로 반환을 해줍니다. 그렇지 않을 경우에는 arr의 인덱스로 numOfData로 넣어주고 LData로 가져온 data을 arr에 저장합니다. 그리고 numOfData를 증가해줍니다.
배열 기반 리스트의 조회

저장된 데이터가 없으면 조회할 데이터가 없기 때문에 FALSE로 return 한다. LFirst, 첫 번째 데이터를 참조하기 때문에, curPosition은 0으로 참조 위치를 초기화합니다.
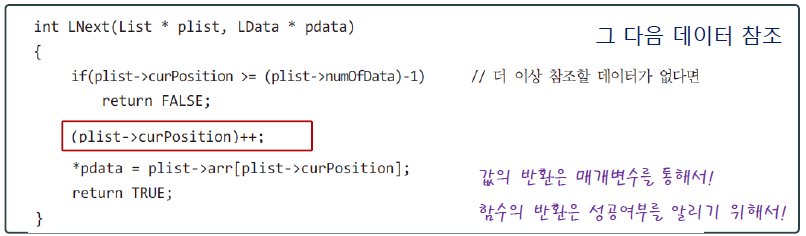
더 이상 참조할 데이터가 없다면 FALSE로 return 하게 하고, 참조할 데이터가 있다면 curPosition을 증가시켜 다음 데이터를 참조할 수 있게 하고 TRUE를 반환합니다.
배열 기반 리스트의 삭제
배열은 메모리 특성상 삭제 후 유효한 데이터를 채워 넣지 않으면 관리하기 힘들다.

삭제할 데이터의 인덱스 값을 참조하여 그 위치에 한 칸 앞에 있는 데이터를 이동시켜서 넣어줍니다. 이것이 삭제 기본 모델입니다. 끝에 있는 값까지 모두 이동시켰으면 데이터의 수를 1 감소시키고 참조 위치도 하나 감소시켜 앞으로 이동시킵니다. 마지막으로는 rdata로 return 하여 삭제된 데이터를 반환시킵니다. (삭제된 것의 데이터를 확실하게 알게 함)
참조 위치를 감소시키지 않으면 삭제 이후 D를 가리키고 이후 LNext를 통해 E를 참조하게 됩니다. D를 참조하지 않고 넘겨지게 되는 것이죠. 그래서 curPosition을 하나 감소시켜 D도 참조할 수 있게 합니다.
리스트에 구조체 변수 저장하기
리스트에 저장할 Point 구조체 변수의 헤더 파일 선언
typedef struct _point
{
int xpos;
int ypos;
} Point;
// Point 변수의 xpos, ypos 값 설정
void SetPointPos(Point * ppos, int xpos, int ypos);
// Point 변수의 xpos, ypos 정보 출력
void ShowPointPos(Point * ppos);
// 두 Point 변수의 비교
int PointComp(Point * pos1, Point * pos2);
구조체 Point 관련 소스파일
void SetPointPos(Point * ppos, int xpos, int ypos) {
ppos->xpos = xpos;
ppos->ypos = ypos;
}
void ShowPointPos(Point * ppos) {
printf("[%d, %d] \n", ppos->xpos, ppos->ypos);
}
int PointComp(Point * pos1, Point * pos2) {
if(pos1->xpos == pos2->xpos && pos1->ypos == pos2->ypos)
return 0;
else if(pos1->xpos == pos2->xpos)
return 1;
else if(pos1->ypos == pos2->ypos)
return 2;
else
return 1;
}
ArrayList.h의 변경 사항 두 가지

typedef 선언에서 보이듯이 실제로 저장을 하는 것은 Point 구조체 변수의 주소 값이다!
실행을 위한 파일 구성


PointListMain.c의 일부
초기화 및 저장
int main(void)
{
List list;
Point compPos;
Point * ppos;
ListInit(&list);
/*** 4개의 데이터 저장 ***/
ppos = (Point*)malloc(sizeof(Point));
SetPointPos(ppos, 2, 1);
LInsert(&list, ppos);
ppos = (Point*)malloc(sizeof(Point));
SetPointPos(ppos, 2, 2);
LInsert(&list, ppos);
. . . . . .
}List 구조체 변수 list를 선언해주고 ListInit으로 해당 list를 초기화 후 동적 할당을 통해 데이터를 저장해줍니다. 지금 포인터 구조체 변수의 주소 값이 ppos에 저장되어있는 상태입니다.
참조 및 조회
int main(void)
{
. . . . .
/*** 저장된 데이터의 출력 ***/
printf("현재 데이터의 수 : %d \n", LCount(&list);
if(LFirst(&list, &ppos))
{
ShowPointPos(ppos);
while(LNext(&list, &ppos))
showPointPos(ppos);
}
printf("\n");
. . . . .
}위에서 동적 할당을 해줘서 구조체 변수의 멤버(showPointPos(ppos)를 사용)를 출력하게 할 수 있습니다. 위에 배열에서는 &data으로 데이터를 참조했지만 여기서는 구조체 변수를 동적 할당받아서 데이터를 참조합니다.
삭제
int main(void)
{
. . . . .
/*** xpos가 2인 모든 데이터 삭제 ***/
compPos.xpos=2;
compPos.ypos=0;
if(LFirst(&list, &ppos)) {
if(PointComp(ppos, &compPos)==1) {
ppos=LRemove(&list);
free(ppos);
}
while(LNext(&list, &ppos)) {
if(PointComp(ppos, &compPos)==1) {
ppos=LRemove(&list);
free(ppos);
}
}
}
. . . . .
}PointComp은 삭제하고 싶은 위치를 잡아내서 삭제하고 싶은 것과 동일하면 삭제할 수 있게 1을 반환합니다. 그래서 compPos.xpos, compPos.ypos로 지정해놓은 값을 삭제할 수 있게 됩니다. 그리고 삭제하고 나서 받은 주소 값은 free로 동적 할당을 해제해줍니다.
리스트 자료형의 책임에는 그 주소 값과 관련된 메모리의 해제는 포함되어 있지 않습니다. 그렇기 때문에 LRemove는 삭제된 해당 주소 값을 반환해줘서 ppos로 담아서 free를 해줘야 합니다. 그렇지 않으면 메모리 누수가 생기게 됩니다.
배열 기반 리스트의 장점과 단점
배열 기간 리스트의 단점
- 배열의 길이가 초기에 결정되어야 한다. 변경이 불가능하다.
- 삭제의 과정에서 데이터의 이동(복사)이 매우 빈번히 일어난다.
배열의 일반적인 단점
배열 기반 리스트의 장점
- 데이터 참조가 쉽다. 인덱스 값 기준을 어디든 한 번에 참조 가능!
배열 기반으로 리스트가 구현이 되었을 때 참조가 쉽기 때문에 ADT에 이와 관련된 함수가 추가되기도 한다.
배열의 일반적인 장점
'Data Structures' 카테고리의 다른 글
| [Data Structures][04-2] 단순 연결 리스트의 ADT와 구현 [구현중] (0) | 2022.01.24 |
|---|---|
| [Data Structures][04-1] 연결 리스트의 개념적인 이해 (0) | 2021.10.27 |
| [Data Structures][03-1] 추상 자료형 : Abstract Data Type (0) | 2021.10.25 |
| [Data Structures][02-3] 하노이 타워 : The Tower of Hanoi (0) | 2021.10.23 |
| [Data Structures][02-2] 재귀의 활용 (0) | 2021.10.22 |